Much of the policy discourse about AI today is perplexing, and the very idea of “regulating AI” per se (as in California or the EU) doesn’t seem like a sensible regulatory objective.

An initial problem is that “AI” means next to nothing. Everything is AI these days. We’ve all seen instances in which logistic regression or even linear regression (originating in the 1800s) is called “AI.” And the definition in Biden’s Executive Order and in federal law is quite broad:
The term “artificial intelligence” or “AI” has the meaning set forth in 15 U.S.C. 9401(3): a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. Artificial intelligence systems use machine- and human-based inputs to perceive real and virtual environments; abstract such perceptions into models through analysis in an automated manner; and use model inference to formulate options for information or action.
The recent Artificial Intelligence Accountability Policy Report from the National Telecommunications and Information Administration uses that same definition from the Executive Order.
By this definition, pretty much anything is “AI.”
Microsoft Word’s autocorrect from nearly 20 years ago would count as “AI,” because it makes recommendations:
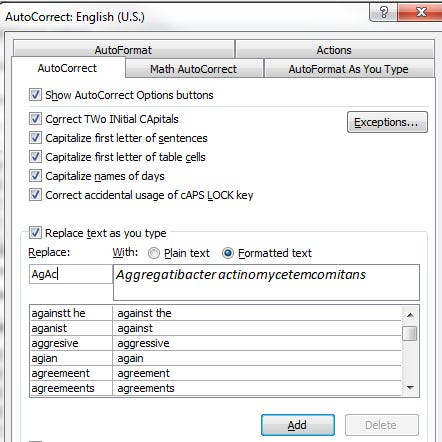
I assume we aren’t looking for expansive regulation of Microsoft Word’s autocorrect function (however irritating it can be sometimes).
Another overly broad definition can be found in Section 238(g) of P.L. 115-232 (the National Defense Authorization Act for 2019):
(1) Any artificial system that performs tasks under varying and unpredictable circumstances without significant human oversight, or that can learn from experience and improve performance when exposed to data sets.
(2) An artificial system developed in computer software, physical hardware, or other context that solves tasks requiring human-like perception, cognition, planning, learning, communication, or physical action.
(3) An artificial system designed to think or act like a human, including cognitive architectures and neural networks.
(4) A set of techniques, including machine learning, that is designed to approximate a cognitive task.
(5) An artificial system designed to act rationally, including an intelligent software agent or embodied robot that achieves goals using perception, planning, reasoning, learning, communicating, decision making, and acting.
Again, pretty much anything could count as “AI” here, especially the 4th category: any “set of techniques” that is “designed to approximate a cognitive task.” What’s the point of all these definitions that are so broad?
Some policymaking documents, as far as I can tell, don’t try to define “AI” at all. Even the Trade and Technology Council’s document on “EU-US Terminology and Taxonomy for Artificial Intelligence” — which lists definitions for several dozen AI-related terms — never gets around to defining “AI” in the first place! (The list of definitions has two terms under A: “adversarial machine learning” and “autonomy”). Nor does the AI Risk Management Playbook (from the National Institute of Standards and Technology, or NIST).
NIST’s “The Language of Trustworthy AI: An In-Depth Glossary of Terms” does have a definition for “artificial intelligence.” In fact, it has five definitions. All of them are even broader than the White House definition (these are all direct quotes, although I’ll omit the quotation marks):
- Interdisciplinary field, usually regarded as a branch of computer science, dealing with models and systems for the performance of functions generally associated with human intelligence, such as reasoning and learning.
- The field concerned with developing techniques to allow computers to act in a manner that seems like an intelligent organism, such as a human would. The aims vary from the weak end, where a program seems “a little smarter” than one would expect, to the strong end, where the attempt is to develop a fully conscious, intelligent, computer-based entity. The lower end is continually disappearing into the general computing background, as the software and hardware evolves.
- The study of ideas to bring into being machines that respond to stimulation consistent with traditional responses from humans, given the human capacity for contemplation, judgment and intention. Each such machine should engage in critical appraisal and selection of differing opinions within itself. Produced by human skill and labor, these machines should conduct themselves in agreement with life, spirit and sensitivity, though in reality, they are imitations.
- A field of study that is adept at applying intelligence to vast amounts of data and deriving meaningful results
- The application of computational tools to address tasks traditionally requiring human analysis.
Overly broad? QED.
***
To a former regulatory lawyer, all of the above is a bit frustrating.
Perhaps the most important task of any regulatory initiative is to carefully and narrowly define what you’re talking about.
It is a bad idea to have no definition of the very thing you’re trying to regulate, or to use definitions that are so loose, broad, poorly-thought-out, and ambiguous that they might include scenarios that you don’t need to (or mean to) regulate. That’s just going to tie everything up in lawsuits in the future, and courts will get to narrow things down to a more rational definition.
Why leave it to the courts? Come up with a solid and defensible definition in the first place.
***
What I just said is a bit glib, however.
Why? It’s actually difficult to define AI in a meaningful sense that deserves regulation in and of itself.
It’s far easier to come up with specific worries about particular use cases, even if they are mostly hypothetical to date.
After all, what does “AI” even mean?
The AI systems we see right now are just math—most commonly, neural networks with a ReLU activation function, with tons of weights plus attention and softmax.
Or to use terms that statisticians might recognize (rather than all the wheel-reinventing terms that the machine learning field comes up with for no apparent reason other than ignorance of what has already been discovered): multi-layered regression with the independent variables constrained to be above zero, with tons of estimated parameters plus kernel smoothing and normalization.
All of this is implemented via software trained on data. Math, software, data — these are foundational ideas or tools that can be used for many purposes from good to bad and everything in between, just like words, wheels, transistors, underseas cables that transmit most Internet traffic, spreadsheets, etc.
But there’s nothing here that would typically make sense to regulate directly!
For example:
- Words can be used in everything from a Shakespearean sonnet to hiring a hitman or committing fraud. We don’t therefore set up a National Words Committee to consider how to regulate “words” per se.
- Wheels can be used for an ambulance taking someone to the hospital, or for military tanks invading a helpless country for no reason. We don’t therefore set up a National Wheels Committee to analyze the dangers of wheels.
- Internet traffic via underseas cables can be used for all sorts of purposes—enabling communications between prize-winning scientists and their colleagues, or sending illegal payments to a hitman. We don’t need to set up a National Undersea Cables Committee to prevent all the potential dangers from the Internet by putting some artificial limit on the transmission capacity of underseas cables.
- Spreadsheets can be used for legitimate business purposes, or for engaging in financial fraud like Bernie Madoff. Regulating spreadsheets per se isn’t a useful idea, as opposed to regulating fraud. A National Committee on Spreadsheets would likely find itself confused as to its actual mission.
The same goes for math and software as embodied in whatever anyone wants to call “AI.” Math and software can be used for everything from planning a mission to Mars, to engaging in cyberattacks on nuclear power plants. That doesn’t mean we need to “regulate math and software” per se.
Instead, we need to define the more specific scenarios of actual harm, and regulate those use cases directly rather than trying to regulate broad and largely irrelevant proxies.
Indeed, there’s a good argument that we’re already doing just that.
A few examples:
Fraud

Wire fraud is already illegal. If someone uses generative AI to create a persuasive message or video that fools someone else into transferring money, that is illegal. It’s not clear why we need an “AI-specific” version of wire fraud or any other instances of fraud.
Math can be used in the commission of fraud, yes, but so can printed words, conversations, the ACH system, spreadsheets, checks, credit cards, the Internet (and hence transmission towers, underseas cables, etc.), and more. That doesn’t mean we need a national order on “Regulation of Words,” or a national institute on “Spreadsheet Safety.” Any of that would be too broad, ill-specified, and at the wrong level to actually focus on fraud.
If you want to regulate fraud, regulate fraud and only then consider all the means and mechanisms by which fraud might occur. If you want to update fraud laws to add extra penalties for AI cases (on the theory that they’re more dangerous and widespread), go for it, but the focus should be first on fraud and secondarily on the mechanisms (rather than the reverse).
Bioweapons

Another commonly-expressed fear is that AI might someday make it easier for untrained folks to build a bioweapon and use it for terrorism. Making a bioweapon and killing people is already illegal under quite a few laws, and it’s unclear why this scenario is a reason to regulate basically any use of a computer.
After all, there are lots of other things that make it easier to create bioweapons, far more directly than LLMs:
- Biomedical labs
- Manufacturers of lab equipment
- Scientific publications on CRISPR, recombinant DNA, etc., etc.
- Universities that offer biology degrees
- The Internet
- The NIH (which maintains a website where you can read the entire smallpox genome as well as Ebola)
- Libraries
- Biology textbooks
In fact, if not for all of these publicly available resources, LLMs would have precisely zero information about bioweapons, lab techniques, and the like.
So far, we haven’t regulated at the highest and most abstract level about words, information, ideas, or infrastructure. Our laws and regulations are more tailored to specific use cases.
For example, there’s a specific federal law making it illegal to possess or transport any “biological agent” described in 42 C.F.R. Part 73 (with narrow exceptions for research purposes). What does that regulation include? Here’s a (partial!) list of forbidden substances:
Abrin
Bacillus cereus Biovar anthracis*
Botulinum neurotoxins*
Botulinum neurotoxin producing species of Clostridium*
Conotoxins (Short, paralytic alpha conotoxins containing the following amino acid sequence X1CCX2PACGX3X4X5X6CX7)[1]
Coxiella burnetii
Crimean-Congo hemorrhagic fever virus
Diacetoxyscirpenol
Eastern equine encephalitis virus
Ebola virus*
Francisella tularensis*
Lassa fever virus
Lujo virus
Marburg virus*
Monkeypox virus
Reconstructed replication competent forms of the 1918 pandemic influenza virus containing any portion of the coding regions of all eight gene segments (Reconstructed 1918 influenza virus)
Ricin
Rickettsia prowazekii
SARS coronavirus (SARS-CoV)
SARS-CoV/SARS-CoV-2 chimeric viruses resulting from any deliberate manipulation of SARS-CoV-2 to incorporate nucleic acids coding for SARS-CoV virulence factors.
Saxitoxin
South American hemorrhagic fever viruses:
Chapare
Guanarito
Junin
Machupo
Sabia
Staphylococcal enterotoxins (subtypes A-E)
T-2 toxin
Tetrodotoxin
Tick-borne encephalitis virus
Far Eastern subtype
Siberian subtype
Kyasanur Forest disease virus
Omsk haemorrhagic fever virus
Variola major virus (Smallpox virus)*
Variola minor virus (Alastrim)*
Yersinia pestis*
That is a regulation that is targeted at the right level.
Note that no one says, “Aha, the problem here is that people are allowed to say words to each other.” No one sets up a committee to try to regulate all textbooks and articles, or even the entire Internet, to make it presumptively illegal to use words to tell anyone about any biological technique or equipment that could ever be used in a potentially harmful way.
That would be overkill, and it would also likely be unenforceable.
It would also be pointless: There are already detailed protocols available online for how to create viruses, and would-be terrorists without specialized training or access to a sophisticated lab have zero ability to do any of this. It is almost inconceivable that an LLM would make any difference: written instructions aren’t the chokepoint here.
Medical Products
“AI” products could have a huge impact on health—but not always positive.
This isn’t because “AI” is qualitatively different from previous recommendation algorithms (e.g., what used to be called “clinical decision support” tools before “AI” became the trendy term).
Instead, it’s because most such tools are low-quality, overfitted to their training set, irreproducible, or clinically useless for any number of other reasons.
A typical headline in this area:

Don’t get me wrong, “AI” tools have potential to improve cancer diagnosis and imaging, among other things (see here). The only point is that to the extent we want anyone to regulate “AI” systems used in medicine, so as to make sure they actually work and aren’t killing people by misdiagnosis or mistreatment, that should probably be the FDA.
And that’s exactly what the FDA is already doing. Just in March, the FDA released this overview paper on what its various offices and centers have been doing to ensure that automated algorithms are actually beneficial to human health.
One can have any number of philosophical disagreements with the FDA, but still think that their approach is likely more targeted and useful than whatever we might get from any new organization, legislation, or committee (with little or no expertise in medicine) that is looking into regulating all uses of math and software.
An Objection
“You said that AI is just math. We might also say that the human brain at its most basic level is just math. That doesn’t mean it is harmless. Intelligence can be put to all sorts of evil ends.”
Good point. What I mean to say isn’t, “AI is math and therefore harmless,” but rather, “AI is math, just as synaptic processing can be represented in some sense by math, and both should be regulated the same way.”
That is, both can be used for great harm, great good, and anything in between. The only way we can possibly regulate the harms is at the emergent level. In both cases:
- We don’t know (and may never know) how the reductionist details actually matter to the emergent level, and therefore,
- A reductionist regulation would be mistargeted at best, and might even prevent much good.
After all, how do we regulate and discuss all the many ways in which human brains can be used for ill? Not by setting up a National Synapse Committee or a National Dopamine Safety Initiative.
No neuroscientist would have the slightest idea how to directly regulate the arrangement of synapses or the ways in which the brain processes dopamine. Similarly, no one knows how to regulate anything at the level of linear algebra or GPUs.
Instead, we regulate human intelligence at the emergent level where harm is actually possible: criminal law, environmental law, securities law, campaign finance law, and so forth.
Another Objection
The most salient regulatory debate right now is over California’s Senate Bill 1047 as well as the EU Artificial Intelligence Act, both of which have a much more narrowly targeted definition of the AI models to be regulated. So, who cares if other definitions are too broad?
Fair point. California’s bill currently defines the relevant AI models like this:
(i) An artificial intelligence model trained using a quantity of computing power greater than 10^26 integer or floating-point operations, the cost of which exceeds one hundred million dollars ($100,000,000) when calculated using the average market prices of cloud compute at the start of training as reasonably assessed by the developer.
(ii) An artificial intelligence model created by fine-tuning a covered model using a quantity of computing power equal to or greater than three times 10^25 integer or floating-point operations.
The putative worry behind the bill is to prevent “critical harms,” which include things like “mass casualties or at least five hundred million dollars ($500,000,000) of damage resulting from cyberattacks.” And in very similar terms, the EU Act is concerned with the following sort of dangerous AI models:
A general-purpose AI model shall be presumed to have high impact capabilities pursuant to paragraph 1, point (a), when the cumulative amount of computation used for its training measured in floating point operations is greater than 10(^25).
But setting a regulatory threshold based on floating point operations or the cost of computational power seems quite odd in at least three ways.
First, thresholds like 10^26 or 10^25 were pulled out of thin air. There’s no logic or basis for those numbers other than the fact that someone at one point in time thought they were really big numbers (h/t Rohit for the links there).
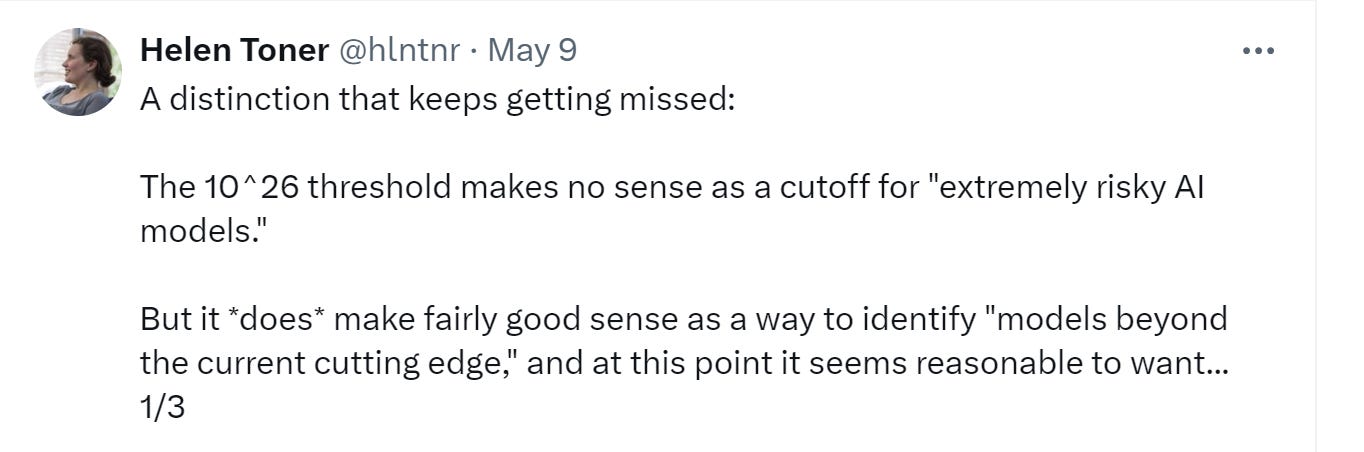
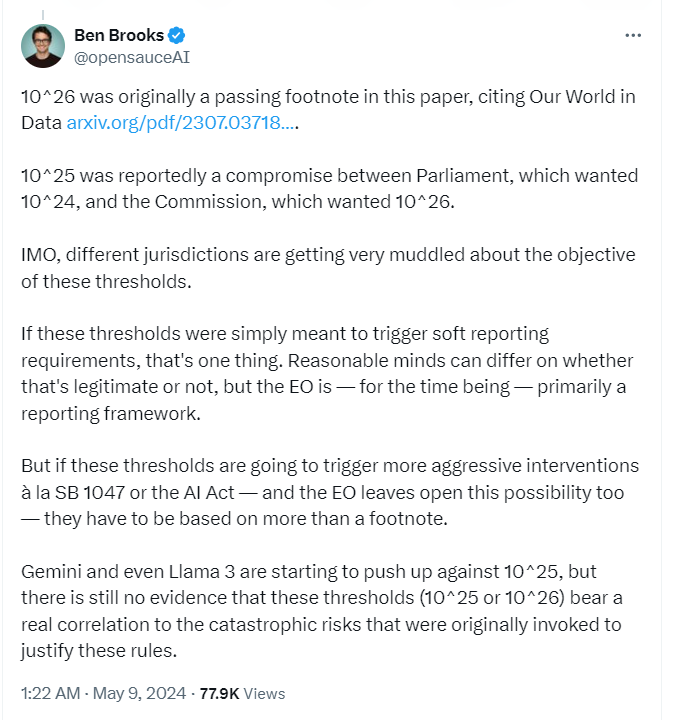
Second, if there ever exists any such thing as a serious risk of “critical harms” from AGI models, those models might look far different from the increasingly expensive models seen today. Your brain can be powered each day with a few hundred calories of energy, and it didn’t need $100 million dollars plus trillions of tokens of training material. Why are we so sure that a silicon form of general intelligence will necessarily be so expensive and data-intensive?
Maybe we’re on the wrong track, and the real path to AGI will come through developing much more efficient algorithms. Maybe John Carmack is right that “it is likely that the code for artificial general intelligence is going to be tens of thousands of lines of code, not millions of lines of code,” and that all we’re lacking are a few key insights that could be “written on the back of an envelope.” Alternatively, imagine something like Stuxnet but with more agency/autonomy to select amongst governmental targets—that seems much more dangerous than LLMs (at present) but would involve much less compute. In other words, the 10^26 threshold might be superceded by dangerous “AI” models that are nowhere near that threshold.
Third, maybe it is indeed the case that scaling up current models/data is the path to AGI. But if scale is the main or only factor, then why these particular thresholds? Who knows, the actual threshold for AGI might be orders of magnitude higher in terms of floating point operations. After all, the most recent version of LLaMA already exceeds some of the training thresholds in California or EU legislation: it required “over 16 thousand H100 GPUs” (which would apparently cost some $400 million dollars), and was “pre-trained using 3.8 × 10^25 FLOPs, almost 50× more than the largest version of Llama 2.”
Is there any reason to think that LLaMA is anywhere near AGI, or that it poses any risk of creating catastrophic harm? Not that I’ve seen, any more than it was correct to worry in early 2019 that GPT-2 was too dangerous to release.
In short, trying to regulate AI based on the number of floating point operations seems like trying to regulate wire fraud based on the number of kilowatt/hours of electricity used by an office building.
There is no reason to think that fraud is less of a risk under a particular kilowatt/hour threshold, nor is there any reason to think that office buildings that use more electricity (perhaps because of their size or the local environment) are more likely to be engaged in fraud.
If you want to regulate fraud, you can do so directly, and there is no need to confuse things by focusing on the amount of electricity or math being used.
Conclusion
AI regulation should be well-defined and targeted at the right level, in ways that are enforceable and aren’t going to lead to endless litigation about overly broad or meaningless definitions. The California/EU approach seems likely to be viewed someday as irrelevant and/or harmful.