by Stuart Buck

If you like this, subscribe to the newsletter.
There are several scientific funding efforts being created at the moment — e.g., ARPA-H (the DARPA for health), the UK’s Advanced Research and Invention Agency (ARIA), and the National Science Foundation’s Technology, Innovation and Partnerships directorate (TIP).
This is all terrifically exciting!
But there’s a crucial question: How will we know whether anything works?
It would be a shame to spend all of this money, effort, and thought to set up new scientific funding initiatives, only to get 5 or 10 years down the road and be unsure whether we made any difference.
One essential lesson for these agencies:
CREATE VARIATION.
Don’t just do everything the same way. Find ways to vary what you do. Better yet, use cutoffs (such as peer review scores). Better yet, use deliberate randomization where it’s feasible and makes sense. But variation is the key. Without variation, we can’t possibly measure whether one approach is better than another.
For an example of how this plays out, let’s look at a recent study titled, “Opening up Military Innovation: Causal Effects of Reforms to U.S. Defense Research,” by Sabrina Howell, Jason Rathje, John Van Reenen, and Jun Wong.
This paper was the “first causal analysis of a defense R&D program.”
Here’s their motivating question:
A key decision is whether to take a centralized approach where the desired innovation is tightly specified or to take a more open, decentralized approach where applicants are given leeway to suggest solutions. There are trade-offs. The open approach may result in too many suggestions that are not useful to the funder, whereas the centralized approach may work poorly if there is uncertainty about what opportunities exist, and may result in insularity if a small group of firms specializes in the specified projects.
The authors note that a quasi-experiment occurred within the Small Business Innovation Research program from the US Air Force. Every few months, the Air Force holds a competition for firms to create various military technologies. The traditional or conventional approach is to be very specific, such as asking firms to create “Affordable, Durable, Electrically Conductive Coating or Material Solution for Silver Paint Replacement on Advanced Aircraft.”
But after 2018, the Air Force included an “Open” part of the competition where “firms could propose what they thought the [Air Force] would need.” The solicitation directly mentioned “unknown unknowns,” to echo Donald Rumsfeld’s famous phrase.
At this point, empirical scholars’ eyes will light up: here is some variation that might be possible to study. Is it better to be highly specific and top-down in asking someone to develop a very particular technology, or is it better to let them come up with new ideas on their own?
The authors had data on 19,500 proposals from around 6,500 firms (including “7,300 proposals across 3,200 firms in the baseline 2017-19 sample when Open and Conventional were run simultaneously”).
What happened next? The Open program “reached a dramatically different type of firm,” namely firms that were “about half as old, half as large, less likely to have previous defense contracts, and more likely to be located in high tech entrepreneurial hubs.”
OK, so the Open and Conventional programs drew different applicants. What were the results?
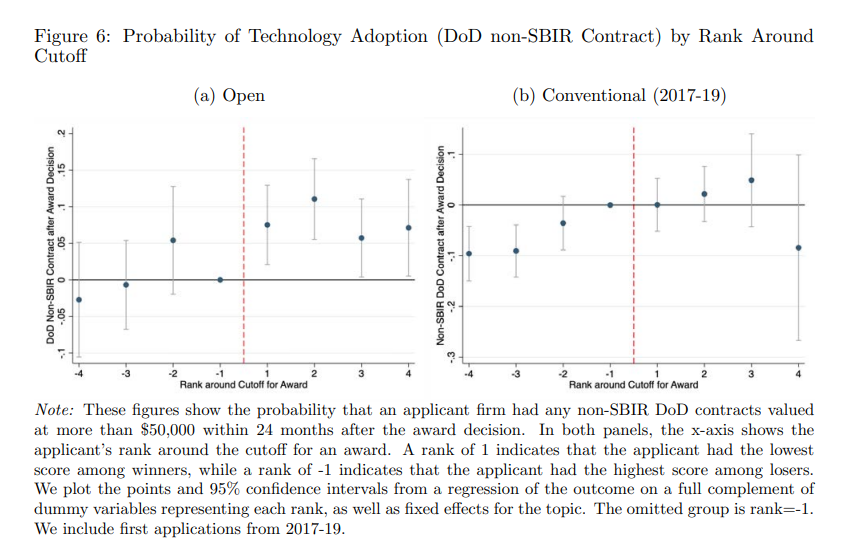
The headlining result is that getting an award in the Open competition had significant effects on three outcomes: 1) a 7.5 percentage point increase that the military would later adopt the new technology;
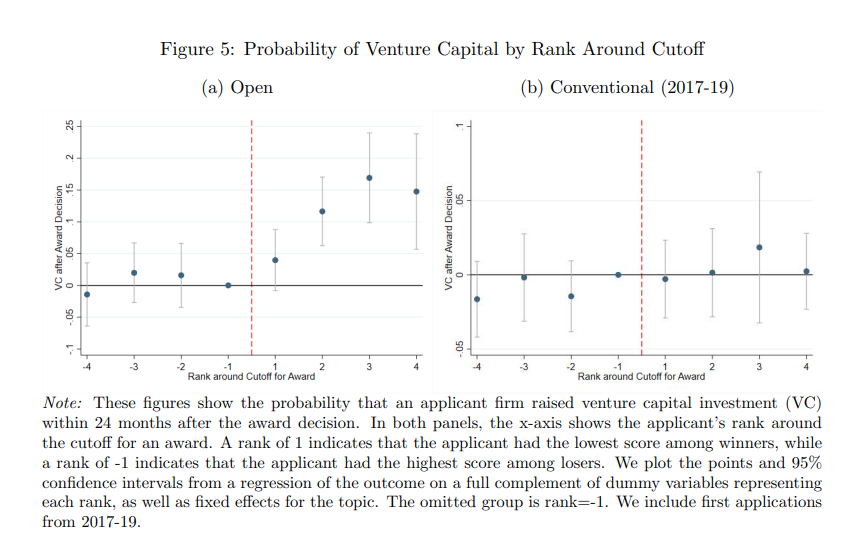
2) a 5.2 percentage point increase in the likelihood of later venture capital investments;
and 3) probability of patents.
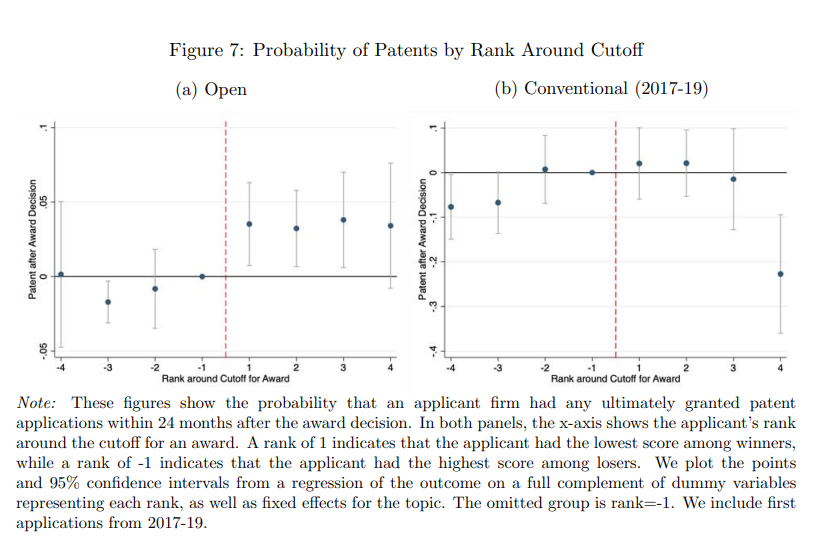
By contrast, say the authors, “winning a Conventional award has no measurable effects on any of these outcomes.” The only place where winning a Conventional award had an impact was on the chance of winning a future Small Business Innovation Research award–but that isn’t a good thing! It “creates lock-in and insularity.”
They conclude that “the Open program seems to work in part because it provides firms with an avenue to identify technological opportunities about which the government is not yet fully aware.”
How did the authors know any of this?
They used a regression discontinuity design. That means there were scores used to rank the proposals, with a cutoff somewhere in the middle. Regression discontinuity just means looking at what happens to people just above the cutoff versus just below the cutoff.
Wait a minute, you might say: Perhaps the firms that apply to an Open competition are just fundamentally different from the other firms, even in ways that can’t be measured.
But the authors do some robustness tests where they show that even for firms that apply to both types of competitions, winning the Open competition has “significantly larger effects” on venture capital and subsequent Defense contracts.
This is “remarkable” because firms that apply to both programs seem to be “specialists who apply to as many topics as possible.”
In other words, the finding seems fairly robust.
*********
What can we learn from this study?
A narrow finding is that an open-ended competition might draw in more diverse and productive ideas than trying to specify everything in detail.
But the broader point is this:
Vary what you do. Don’t do everything the same way. Try out different ways of doing peer review (consensus versus non-consensus), or different ways of identifying the problem (top-down versus bottom-up), or different ways of managing grantees (hands-on versus hands-off), or what-have-you.
The Air Force program here wouldn’t be as useful if it did everything the same way, after all. If they ran everything through the Conventional program OR the Open program, no one would know the difference.
The only way you can learn which of two or more funding models is better is to use two or more funding models in the first place. And these new funding agencies offer a golden opportunity to experiment with a variety of funding models that could then inform the rest of scientific funding.
[…] 3. Advice for science funders: vary what you do. […]